Sequential Decisions based on Algorithmic Probability
Order Information
Title: Universal Artificial Intelligence
Subtitle: Sequential Decisions based on Algorithmic Probability
Publisher: Springer,
ISBN: 3-540-22139-5,
DOI: 10.1007/b138233
Date: © 2005,
Pages: 300
The book can be ordered from
springer.com,
or amazon.com,
or amazon.de,
or most other
bookshops.
Abstract
This book presents sequential decision theory from a
novel algorithmic information theory perspective. While the former
is suited for active agents in known environments, the
latter is suited for passive prediction in unknown environments.
The book introduces these two well-known but very different ideas
and removes the limitations by unifying them to one parameter-free
theory of an optimal reinforcement learning agent embedded in an
arbitrary unknown environment. Most if not all AI problems can
easily be formulated within this theory, which reduces the
conceptual problems to pure computational ones. Considered
problem classes include sequence prediction, strategic games,
function minimization, reinforcement and supervised learning. The
discussion includes formal definitions of intelligence order
relations, the horizon problem and relations to other approaches
to AI.
One intention of this book is to excite a broader AI
audience about abstract algorithmic information theory concepts,
and conversely to inform theorists about exciting applications to
AI.
Keywords:
Artificial intelligence;
algorithmic probability;
sequential decision theory;
Solomonoff induction;
Kolmogorov complexity;
Bayes mixture distributions;
reinforcement learning;
universal sequence prediction;
tight loss and error bounds;
universal Levin search;
strategic games;
function minimization;
supervised learning;
adaptive control theory;
rational agents;
exploration versus exploitation.
Short Table of Contents
- A Short Tour through the Book
- Simplicity & Uncertainty
- Universal Sequence Prediction
- Agents in Known Probabilistic Environments
- The Universal Algorithmic Agent AIXI
- Important Environmental Classes
- Computational Aspects
- Discussion
Introduction
Motivation.
The dream of creating artificial devices which reach or outperform
human intelligence is an old one.
What makes this challenge so interesting? A solution would have
enormous implications on our society, and there are reasons to
believe that the AI problem can be solved in my expected lifetime.
So, it's worth sticking to it for a lifetime, even if it takes
30 years or so to reap the benefits.
What is (Artificial) Intelligence?
The science of Artificial
Intelligence (AI) might be defined as the construction
of intelligent systems and their analysis. A natural definition of systems
is anything that has an input and an output stream. Intelligence is more
complicated. It can have many faces like creativity,
solving problems, pattern
recognition, classification,
learning, induction,
deduction, building
analogies, optimization,
surviving in an environment, language
processing, knowledge and
many more. A formal definition incorporating every aspect of intelligence,
however, seems difficult. Further, intelligence is graded, there is a
smooth transition between systems, which everyone would agree to be not
intelligent and truly intelligent systems. One simply has to look in
nature, starting with, for instance, inanimate crystals, then come
amino-acids, then some RNA fragments, then viruses, bacteria, plants,
animals, apes, followed by the truly intelligent homo sapiens, and
possibly continued by AI systems or ET's. So the best we can expect to
find is a partial or total order relation
on the set of systems, which orders them w.r.t. their degree
of intelligence (like intelligence tests do for human systems,
but for a limited class of problems). Having this order we are, of course,
interested in large elements, i.e. highly intelligent systems. If a
largest element exists, it would correspond to the
most intelligent system that could exist.
No Intelligence without Goals.
Most, if not all known facets of intelligence can be formulated as goal
driven or, more generally, as maximizing
some utility function. It is, therefore, sufficient to study
goal driven AI. E.g. the (biological) goal of animals and humans is to
survive and spread. The goal of AI systems should be to be useful to
humans. The problem is that, except for special cases, we know neither the
utility function, nor the environment in which the system will operate, in
advance. The mathematical theory, coined AIXI, is supposed to solve these problems.
Mathematical AI.
Assume the availability of unlimited computational resources. The
first important observation is that this makes the AI problem not
trivial. Playing chess optimally or solving NP-complete problems
become trivial, but driving a car or surviving in nature don't.
The reason being, that it is a challenge itself to well-define
these problems, not to mention to present an algorithm. In other
words: The AI problem has not yet been well-defined. One may view
AIXI as a suggestion for such a mathematical definition of AI.
The universal algorithmic agent AIXI.
AIXI is a universal theory of sequential decision making akin to
Solomonoff's celebrated universal theory of induction. Solomonoff
derived an optimal way of predicting future data, given previous
observations, provided the data is sampled from a computable
probability distribution. AIXI extends this approach to an optimal
decision making agent embedded in an unknown environment.
The main idea
is to replace the unknown environmental distribution
in the Bellman equations by a suitably generalized
universal Solomonoff distribution ξ. The state space is the
space of complete histories. AIXI is a universal theory without
adjustable parameters, making no assumptions about the environment
except that it is sampled from a computable distribution.
Modern physics provides strong evidence that this assumption holds
for (the relevant aspects) of our real world.
From an
algorithmic complexity perspective, the AIXI model generalizes
optimal passive universal induction to the case of active agents.
From a decision theoretic perspective, AIXI is a suggestion of a
new (implicit) ``learning'' algorithm that may overcome all
(except computational) problems of previous reinforcement learning
algorithms.
Computational AI.
There are strong arguments that AIXI is the most intelligent
unbiased agent possible in the sense that AIXI
behaves optimally
in any computable environment.
The book outlines for a number of problem
classes, including sequence prediction,
strategic games, function
minimization, reinforcement and supervised
learning, how they fit into the general AIXI model and how AIXI
formally solves them.
The major drawback of the AIXI model is that it is incomputable.
The book also presents
a preliminary computable AI theory. We
construct an algorithm AIXItl,
which is superior to any other time t and space l
bounded agent. The computation time of AIXItl is of
the order t·2l. The constant 2l
is still too large to allow a direct implementation,
but can be reduced in various ways.
An algorithm is presented that is capable of solving all well-defined
problems as quickly as the fastest algorithm computing a
solution to this problem, save for a factor of 1+ε and lower-order
additive terms.
Discussion.
The discussion in the final book chapter includes less technical remarks on
various philosophical issues, including mortal embodied agents,
the future of AI, the free will paradox, the existence of true randomness,
the Turing test, non-computable physics, the number of wisdom, and consciousness.
The AIXI Model in One Line
It is actually possible to write down the AIXI model explicitly in one line, although one
should not expect to be able to grasp the full meaning and power
from this compact representation.
AIXI is an agent that interacts with an environment in cycles k=1,2,...,m. In
cycle k, AIXI takes action ak (e.g. a limb
movement) based on past percepts o1
r1...ok-1 rk-1 as defined below.
Thereafter, the environment provides a
(regular) observation ok
(e.g. a camera image) to AIXI and a
real-valued reward rk.
The reward can be very scarce, e.g.
just +1 (-1) for winning (losing) a chess game, and 0 at all other
times. Then the next cycle k+1 starts. Given the above, AIXI
is defined by
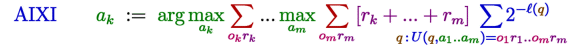
The expression shows that AIXI tries to
maximize its total
future reward rk+...+rm. If the
environment is modeled by a deterministic program q, then the future percepts
...okrk...omrm = U(q,a1..am) can be
computed, where U is a universal (monotone Turing) machine executing
q given a1..am. Since
q is unknown, AIXI has to maximize its expected reward, i.e. average rk+...+rm over all
possible future percepts created by all
possible environments q
that are consistent with past percepts. The
simpler an environment, the higher is its a-priori contribution
2-l(q),
where simplicity is measured by the length l
of program q.
AIXI effectively learns by eliminating
Turing machines q
once they become inconsistent with the progressing history.
Since noisy environments are just mixtures of
deterministic environments, they are automatically included.
The sums in the formula constitute the averaging process. Averaging and maximization have to be performed in
chronological order, hence the interleaving of max and Σ (similarly to minimax for games).
One can fix any finite action and percept space, any
reasonable U, and any large finite lifetime m. This completely and uniquely defines AIXI's actions ak,
which are limit-computable via the expression above (all quantities
are known).
That's it! Ok, not really. It takes a whole book and more to explain and prove why AIXI is the most intelligent general-purpose agent.
In practice, AIXI needs to be approximated.
AIXI can also be regarded as the gold standard which other practical
general purpose AI programs should aim at
(analogue to minimax approximations/heuristics).
Slides
I gave courses based on (parts of) the book to graduate students.
I have prepared nearly 400 slides with exercises,
suitable for at least 30 hours of lectures.
I taught versions of this course
in 2012 at ETH Zürich,
2010-2019 at ANU Canberra,
in 2006 at HeCSE Helsinki,
and in 2003 at TU Munich.
You can find recordings of talks on parts of this material here.
Prizes
I use part of the earnings of the book to offer prizes
for solving some of the open problems stated in the book.
Various problems at the end of most chapters of the book contain
open problems, where the author is not aware of any solution.
Some problems represent mathematically rigorous questions to solve.
In other problems
the task is to make the verbal descriptions or definitions or
ideas itself mathematically rigorous.
Though the monetary reward is not high, it hopefully
serves as an additional motivation (of course you keep the intellectual property).
For determined students these
problems may also be a way toward active research.
Problem 2.3 (Martin-Löf random sequences and convergence)
100 Euro are offered for the construction of a universal semimeasure
with posterior convergence individually for all Martin-Löf random
sequences. Universal may be defined in either of the following ways:
(a) dominating all enumerable semimeasures Eq.(2.27),
(b) being Solomonoff's M for some universal Turing machine U Eq.(2.21),
(c) being Levin's mixture ξU for some U with general weights Eq.(2.26).
See also Problem 3.10 and [P07mlconvxx], and
[P11unipreq] for the (non)equivalence of (a,b,c).
Problem 2.7 (Lower convergence bounds and defect of M)
100 Euro are offered for showing a lower bound for
Mnorm similar to the one given for M,
or for showing an upper bound better than O(2-K(t)).
Problem 2.9 (Prediction of selected bits)
100 Euro are offered for a positive or negative solution for Mnorm.
Another
100 Euro for a positive solution for general
computable selection rules.
This problem has now been solved [P11evenbits].
Problem 3.3 (Comparing two mixtures)
50 Euro
Problem 3.10 (Individual ξ to μ convergence)
See Problem 2.3.
Problem 6.2 (Prediction loss bounds for AIXI)
100-500 Euro.
This is one of the core open questions regarding AIXI.
Proving non-asymptotic value bounds or related optimality properties.
Prize depends on achieved progress in this question.
Problem 6.3 (Posterization of prediction errors)
100 Euro
More prizes may be added, prizes may increase with time, or
may be split or reduced or withdrawn if the solution was essentially already published.
I'm also grateful to receiving worked out solutions in case you
solved some of the other problems including the ones marked with u.
Solutions to Problems
For most problems marked with u I have only handwritten
solutions. I'm grateful to receiving LaTeXed solutions, so
that I can collect and redistribute them to lecturers upon request.
- Problem 2.6 has been solved (2005, by Chernov and myself)
- The Solutions to Problems 2.5 and 2.6u and 2.7u have been TeXed (2005, by myself)
Approximations & Implementations & Applications
The Meanings of AIXI
- AIXI stands for Artificial Intelligence (AI) based on Solomonoff's distribution ξ (Greek letter Xi)
- AIXI stands for Artificial Intelligence (AI) crossed (X) with Induction (I)
- AIXI stands for action ai and percept xi≡oiri in cycle i (see above)
- AIXI is a Catalan word (així) meaning 'in this way' or 'like that' (and with some liberties 'this is it!')
- AIXI is Pinyin romanization (àixī,àixí) of Chinese 愛惜 meaning 'to cherish/treasure' (thanks to Yuxi)
- Pronunciation: aiksi [Latin]
IPA: ['aiksiː]
BibTeX Entry
@Book{Hutter:04uaibook,
author = "Marcus Hutter",
title = "Universal Artificial Intelligence:
Sequential Decisions based on Algorithmic Probability",
publisher = "Springer",
address = "Berlin",
year = "2005",
isbn = "3-540-22139-5",
isbn-online = "978-3-540-26877-2",
pages = "300 pages",
doi = "10.1007/b138233",
url = "http://www.hutter1.net/ai/uaibook.htm",
keywords = "Artificial intelligence; algorithmic probability;
sequential decision theory; Solomonoff induction;
Kolmogorov complexity; Bayes mixture distributions;
reinforcement learning; universal sequence prediction;
tight loss and error bounds; Levin search;
strategic games; function minimization; supervised learning.",
abstract = "This book presents sequential decision theory from a
novel algorithmic information theory perspective. While the former
theory is suited for active agents in known environments, the
latter is suited for passive prediction of unknown environments.
The book introduces these two well-known but very different ideas
and removes the limitations by unifying them to one parameter-free
theory of an optimal reinforcement learning agent interacting with
an arbitrary unknown world. Most if not all AI problems can easily
be formulated within this theory, which reduces the conceptual
problems to pure computational ones. Considered problem classes
include sequence prediction, strategic games, function
minimization, reinforcement and supervised learning. Formal
definitions of intelligence order relations, the horizon problem
and relations to other approaches to AI are discussed. One
intention of this book is to excite a broader AI audience about
abstract algorithmic information theory concepts, and conversely
to inform theorists about exciting applications to AI.",
}
| © 2000 by ... |
| ... Marcus Hutter |

 Order Information
Order Information